所謂的詞向量word embedding就是將詞與詞之間的關係以向量來保留。這樣的數值化資料,可以用來做相似詞推薦,任兩詞的相關性評估。
例如:西瓜 跟 芒果的距離 應該會比 西瓜 跟 軍艦 的距離來得更近
資料來源,以台灣的PTT為例,資料下載自
PTT:
https://tw.pyladies.com/~marsw/dmworkshop.slides.html#/2
Word2Vec範例程式參考自
https://github.com/zake7749/word2vec-tutorial/blob/master/README.md
作法:
使用2016年11月PTT的八卦版資料,含標題與內文。
存成wiki_zh_tw.txt (忽略檔名,跟wiki無關XD)
1.使用jieba 對文本斷詞,並去除停用詞
python3 segment.py
2.使用gensim 的 word2vec 模型進行訓練
python3 train.py
3.測試訓練出的模型
python3 demo.py
輸入一個詞,則去尋找前一百個該詞的相似詞
例如輸入"駭客"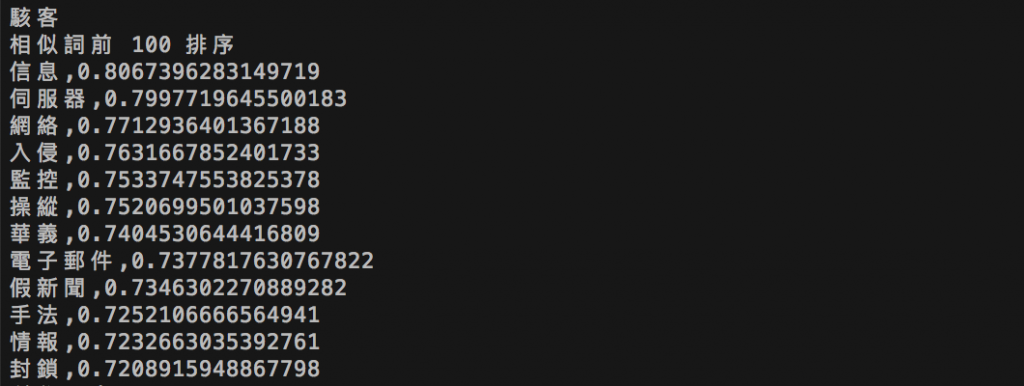
例如輸入"網軍"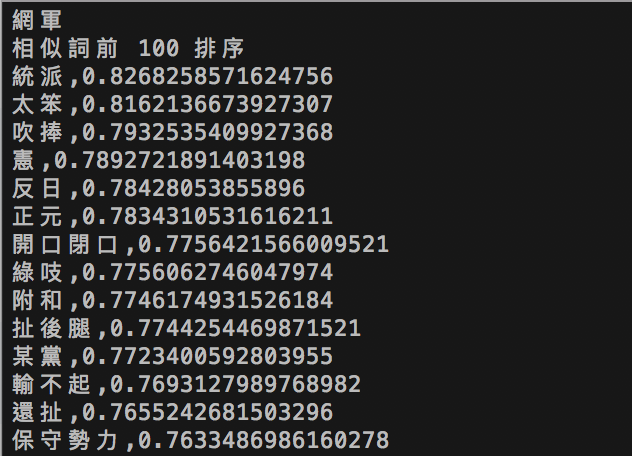
的確可以看到很多相關的詞彙,詞與詞之間的相似度也滿合理的,因此後續便能應用詞向量進行如相似文章分析、文章分類、情緒分析、主題分析等應用。

